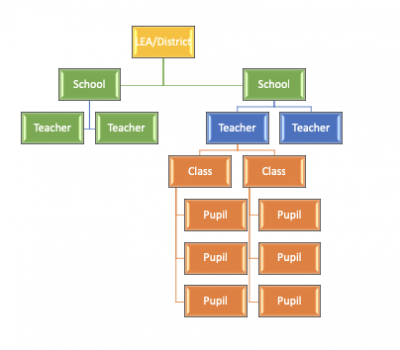
Rule of thumb: You typically need N=10… but 10 what (students?, classrooms?, classes with different teachers?, classes at different schools…)?
Like with Data Reduction, I have started to put these resources into TopHat Chapter 17, so they appear there and here. You can read them either place.
Let’s start with a short (1 paragraph) introduction to the idea of determining the unit of analysis. Let me try to unpack a little more here. Let’s say you try out your technology on your 4th period class, and use your 2nd period class as the comparison. So you are the teacher for both classes and you implement the technology (like using Kahoot! or See Saw) with the whole 4th period class. You get qualitative and quantitative data from the 2 sets of students. So you may think you have all 24 students in each of the classes as your unit of analysis. Not so fast!
You are likely to summarize the qualitative data from each class, and use the mean (average) of the quantitative scores from for your analysis. So there you have only 2 things, one from each class. Maybe your unit of analysis is really classes, not students.
In fact, in 2 Summers, we introduced the idea of the modified ABAB design, where you try some tech with your class using one unit, then do another unit without tech, then back to tech again, then try another without. At the end, if the whole class does better in the units with tech than the ones without, you have some evidence that the tech ‘works.” So you start using it regularly. But if they do better without, it’s time to consider ditching that tech. Here, the unit of analysis is the whole class N=1, and you are doing a single case analysis.
If you had really done this intervention with each individual student, like a drug trial where each patient had an equal chance of getting the drug or a placebo, then definitely your unit of analysis would be student, even if you analyze the mean (average) scores for the 2 classes, to do some summary statistical comparison between the treatment and comparison students.
But, as a researcher, you have to believe that since you are the teacher for all the students, and you implemented the technology by assigning tech to (say ) your 4th period class as a whole (not t0 individuals), then you have to admit it seems like you were dealing with class as your unit of analysis. If true, then a true experiment method would really require you to teach 10 classes using Kahoot, and have 10 comparison classes, to meet the assumption of independence of observations.
Bottom line, as you review your work from the Fall project, consider the question of what really was your unit of analysis.
What do Random Selection and Random Assignment do for a researcher?
Unlike at the casinos, Randomness (chance) is the researcher’s friend when designing a study. Allowing chance to determine who gets into which group (treatment or comparison) and randomly selecting students from the entire population of students can control for many variable that the research could otherwise never control.
- The purpose of random selection is to obtain a truly representative sample from the group to which you would like to generalize your results (such as all 5th graders in our school, or all 5th graders in CT, or all 5th graders in USA, or all k-12 science students, etc.).Discussing the detail of the sample population is an issue for another time and another Stats course.
- The purpose of random assignment (to group) is create 2 truly equal groups prior to your intervention.
Here is a 6 card Quizlet on Random assignment and Random Selection to test your understanding.
Without random selection, you can only make conclusions about the specific students in your study and cannot generalize beyond that to even your next class, let alone to all students in the school or all students in the USA. And without random assignment to the treatment and comparison classes, you may always worry about a confounding variable that made the group different from the start, before you started your intervention.
Random vs Pseudorandom numbers.
Random means you cannot predict the result. Using a programmed computer algorithm to create a random number, is almost by definition, predictable. So how can there be a computer program to produce a random number? This is a question asked by educational research as well as those designing encryption programs to secure our modern smart devices (oh and of course by spies for cybersecurity).
The digits in the decimal expansions of irrational numbers like pi (the ratio of a circle’s circumference to its diameter in a Euclidean plane), e (Euler’s number), or the square roots of numbers that are not perfect squares (such as 2 1/2 or 10 1/2 ) are believed by some mathematicians to be truly random. Thus many simple random number generators use those sequences to give us random numbers. But computers can be programmed to expand such numbers to billions, or even trillions of decimal places, and then sequences can be selected that begin with digits far to the right of the decimal (radix) point, or that use every second, third, fourth, or nth digit. However, again, the use of an algorithm to create a random number is cited by some theoreticians to argue that even these single-digit number sequences are pseudo-random, not truly random. The question then becomes, Is the algorithm accurate (that is, random) to infinity, or not? — and because since we can’t go Back to the Future to find out, the matter becomes purely philosophical.
Truly random numbers, or at least theoretically nearly truly random, can be created using the hardware of devices by exploiting the randomness inherent in their physical systems, such as the optical noise in lasers, radioactive decay in atoms, or the thousandth decimal place of the ticks on your computer’s internal clock. Some random number generators use atmospheric noise to generate randomness, some let you be part of the randomness by putting in a “seed” number. Like many aspects of educational research, even a seemingly simple thing, like randomly picking students for groups, can be a deep topic of debate, theory, and research.
Other Readings:
For a thorough listing of the complex issues in determining the optimal unit of analysis see Dave Kenny’s one-page web page on the topic.
Hopkins, K. (1982) Unit of Analysis: Group means vs Individual Observations, AERJ 19(1), 5-18.
Essential Understanding:
Understanding the level of analysis is critical to designing research with appropriate strategies for random assignment to group and random selection (when possible).
Image Sources
